The upcoming version of Clang 12 includes a new traversal mode which can be used for easier matching of AST nodes.

I presented this mode at EuroLLVM and ACCU 2019, but at the time I was calling it “ignoring invisible” mode. The primary aim is to make AST Matchers easier to write by requiring less “activation learning” of the newcomer to the AST Matcher API. I’m analogizing to “activation energy” here – this mode reduces the amount of learning of new concepts must be done before starting to use AST Matchers.
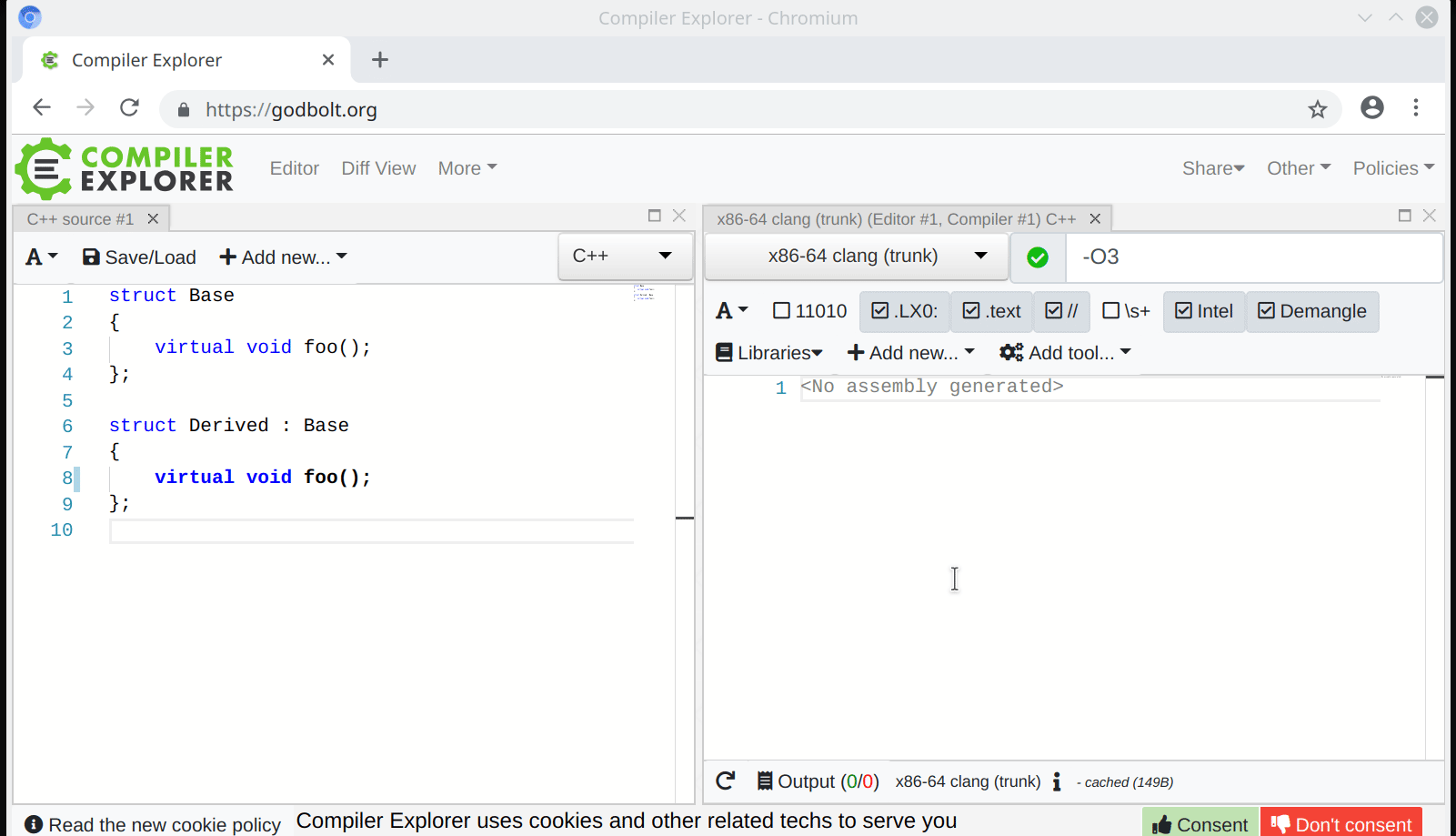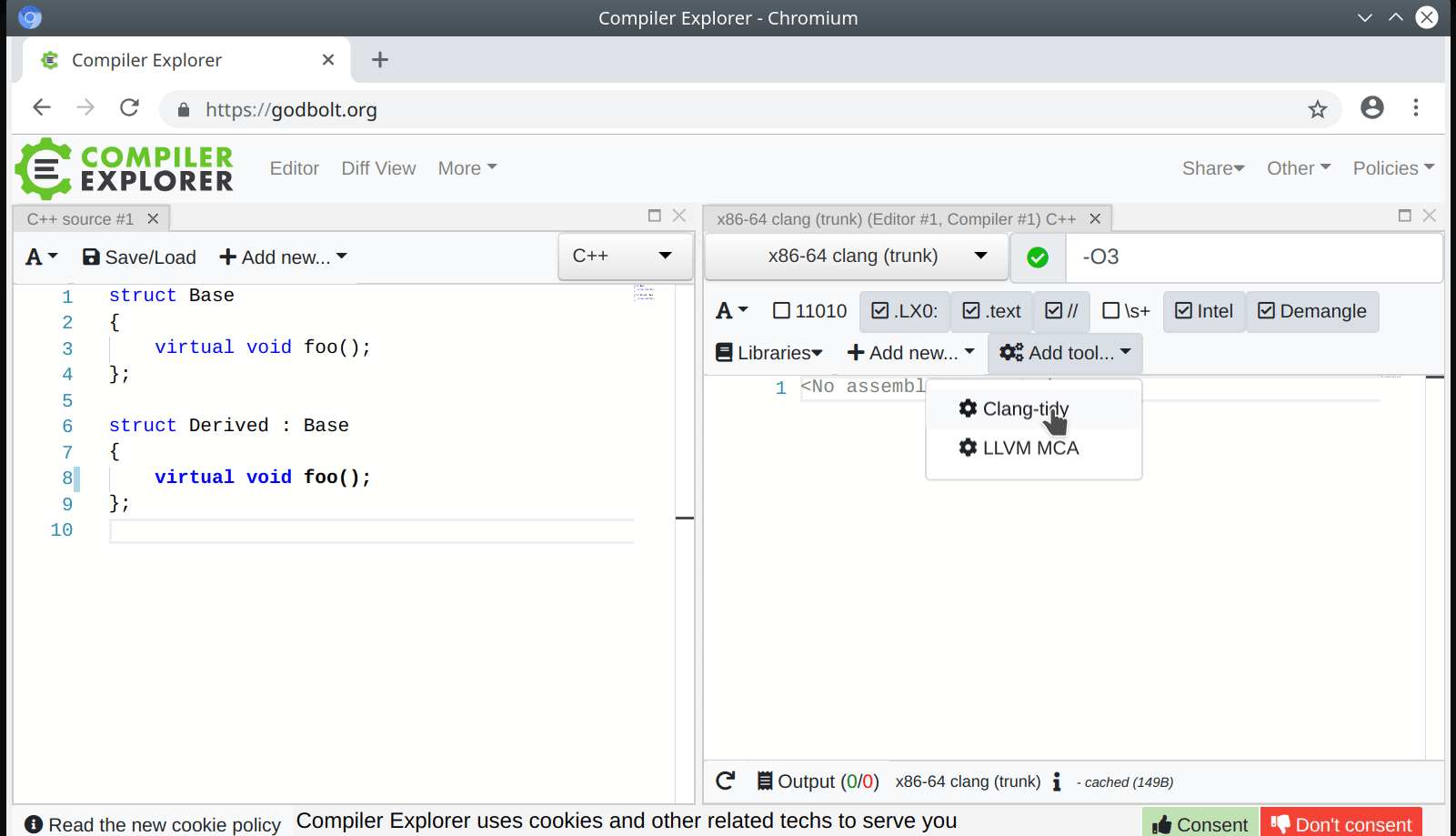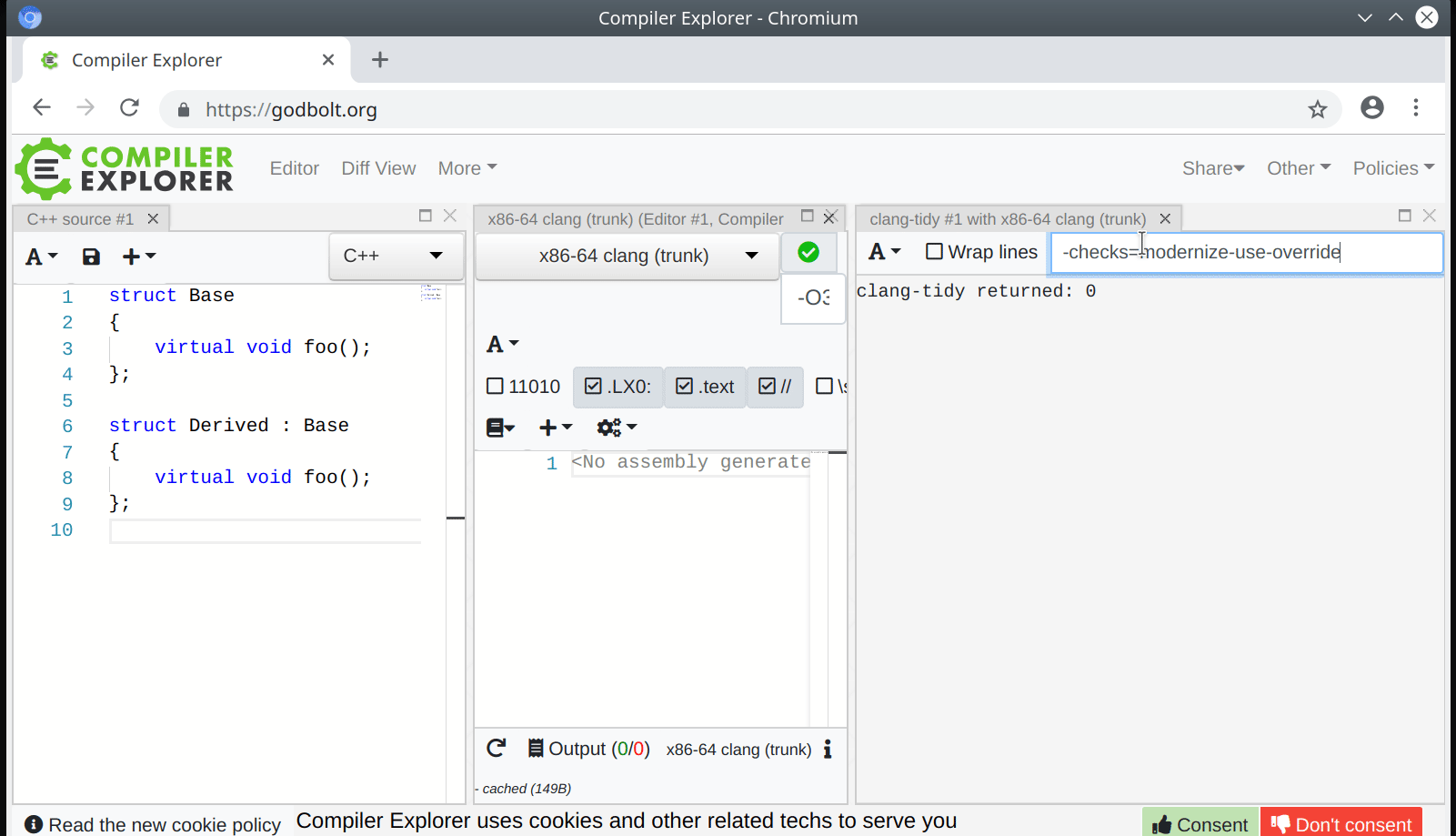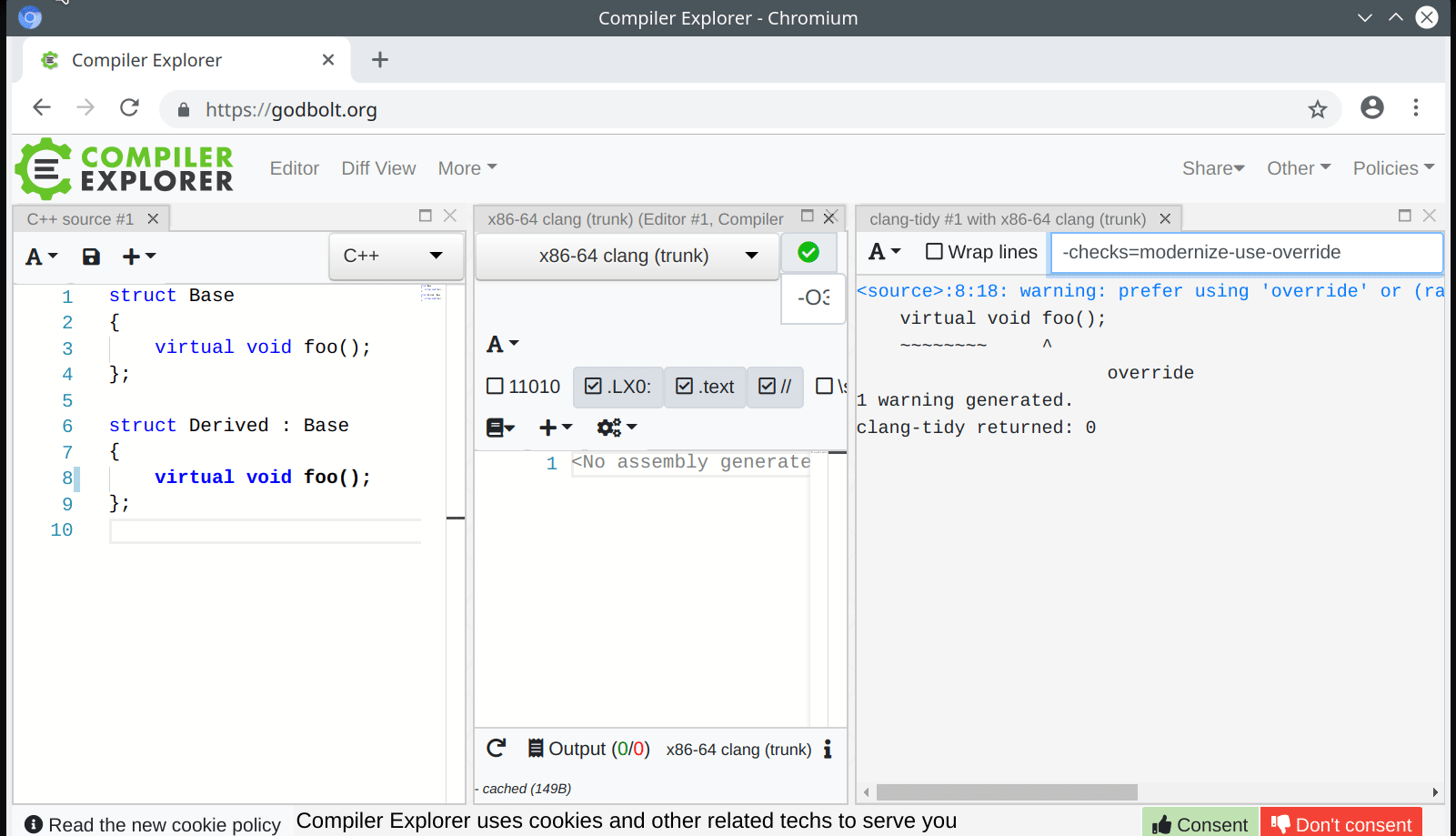
The new mode is a mouthful – IgnoreUnlessSpelledInSource – but it makes AST Matchers easier to use correctly and harder to use incorrectly. Some examples of the mode are available in the AST Matchers reference documentation.
In clang-query, the mode affects both matching and dumping of AST nodes and it is enabled with:
set traversal IgnoreUnlessSpelledInSource
while in the C++ API of AST Matchers, it is enabled by wrapping a matcher in:
traverse(TK_IgnoreUnlessSpelledInSource, ...)
The result is that matching of AST nodes corresponds closely to what is written syntactically in the source, rather than corresponding to the somewhat arbitrary structure implicit in the clang::RecursiveASTVisitor class.
Using this new mode makes it possible to “add features by removing code” in clang-tidy, making the checks more maintainable and making it possible to run checks in all language modes.
Clang does not use this new mode by default.
Implicit nodes in expressions
One of the issues identified is that the Clang AST contains many nodes which must exist in order to satisfy the requirements of the language. For example, a simple function relying on an implicit conversion might look like.
struct A {
A(int);
~A();
};
A f()
{
return 42;
}
In the new IgnoreUnlessSpelledInSource mode, this is represented as
ReturnStmt
`-IntegerLiteral '42'
and the integer literal can be matched with
returnStmt(hasReturnValue(integerLiteral().bind("returnVal")))
In the default mode, the AST might be (depending on C++ language dialect) represented by something like:
ReturnStmt
`-ExprWithCleanups
`-CXXConstructExpr
`-MaterializeTemporaryExpr
`-ImplicitCastExpr
`-CXXBindTemporaryExpr
`-ImplicitCastExpr
`-CXXConstructExpr
`-IntegerLiteral '42'
To newcomers to the Clang AST, and to me, it is not obvious what all of the nodes there are for. I can reason that an instance of A must be constructed. However, there are two CXXConstructExprs in this AST and many other nodes, some of which are due to the presence of a user-provided destructor, others due to the temporary object. These kinds of extra nodes appear in most expressions, such as when processing arguments to a function call or constructor, declaring or assigning a variable, converting something to bool in an if condition etc.
There are already AST Matchers such as ignoringImplicit() which skip over some of the implicit nodes in AST Matchers. Still though, a complete matcher for the return value of this return statement looks something like
returnStmt(hasReturnValue(
ignoringImplicit(
ignoringElidableConstructorCall(
ignoringImplicit(
cxxConstructExpr(hasArgument(0,
ignoringImplicit(
integerLiteral().bind("returnVal")
)
))
)
)
)
))
Another mouthful.
There are several problems with this.
- Typical clang-tidy checks which deal with expressions tend to require extensive use of such
ignoring...() matchers. This makes the matcher expressions in such clang-tidy checks quite noisy
- Different language dialects represent the same C++ code with different AST structures/extra nodes, necessitating testing and implementing the check in multiple language dialects
- The requirement or possibility to use these intermediate matchers at all is not easily discoverable, nor are the required matchers to saitsfy all language modes easily discoverable
- If an AST Matcher is written without explicitly ignoring implicit nodes, Clang produces lots of surprising results and incorrect transformations
Implicit declarations nodes
Aside from implicit expression nodes, Clang AST Matchers also match on implicit declaration nodes in the AST. That means that if we wish to make copy constructors in our codebase explicit we might use a matcher such as
cxxConstructorDecl(
isCopyConstructor()
).bind("prepend_explicit")
This will work fine in the new IgnoreUnlessSpelledInSource mode.
However, in the default mode, if we have a struct with a compiler-provided copy constructor such as:
struct Copyable {
OtherStruct m_o;
Copyable();
};
we will match the compiler provided copy constructor. When our check inserts explicit at the copy constructor location it will result in:
struct explicit Copyable {
OtherStruct m_o;
Copyable();
};
Clearly this is an incorrect transformation despite the transformation code “looking” correct. This AST Matcher API is hard to use correctly and easy to use incorrectly. Because of this, the isImplicit() matcher is typically used in clang-tidy checks to attempt to exclude such transformations, making the matcher expression more complicated.
Implicit template instantiations
Another surpise in the behavior of AST Matchers is that template instantiations are matched by default. That means that if we wish to change class members of type int to type safe_int for example, we might write a matcher something like
fieldDecl(
hasType(asString("int"))
).bind("use_safe_int")
This works fine for non-template code.
If we have a template like
template
struct TemplStruct {
TemplStruct() {}
~TemplStruct() {}
private:
T m_t;
};
then clang internally creates an instantiation of the template with a substituted type for each template instantation in our translation unit.
The new IgnoreUnlessSpelledInSource mode ignores those internal instantiations and matches only on the template declaration (ie, with the T un-substituted).
However, in the default mode, our template will be transformed to use safe_int too:
template
struct TemplStruct {
TemplStruct() {}
~TemplStruct() {}
private:
safe_int m_t;
};
This is clearly an incorrect transformation. Because of this, isTemplateInstantiation() and similar matchers are often used in clang-tidy to exclude AST matches which produce such transformations.
Matching metaphorical code
C++ has multiple features which are designed to be simple expressions which the compiler expands to something less-convenient to write. Range-based for loops are a good example as they are a metaphor for an explicit loop with calls to begin and end among other things. Lambdas are another good example as they are a metaphor for a callable object. C++20 adds several more, including rewriting use of operator!=(...) to use !operator==(...) and operator<(...) to use the spaceship operator.
[I admit that in writing this blog post I searched for a metaphor for “a device which aids understanding by replacing the thing it describes with something more familiar” before realizing the recursion. I haven’t heard these features described as metaphorical before though…]
All of these metaphorical replacements can be explored in the Clang AST or on CPP Insights.
Matching these internal representations is confusing and can cause incorrect transformations. None of these internal representations are matchable in the new IgnoreUnlessSpelledInSource mode.
In the default matching mode, the CallExprs for begin and end are matched, as are the CXXRecordDecl implicit in the lambda and hidden comparisons within rewritten binary operators such as spaceship (causing bugs in clang-tidy checks).
Easy Mode
This new mode of AST Matching is designed to be easier for users, especially newcomers to the Clang AST, to use and discover while offering protection from typical transformation traps. It will likely be used in my Qt-based Gui Quaplah, but it must be enabled explicitly in existing clang tools.
As usual, feedback is very welcome!